基于占位符的自动生成文档脚本的笔记
太长不看版结论
根据实际需求,将文档中需要修改的内容使用占位符代替,例如:{{XXX}}。之后利用Pandas库读取Excel文件获取数据,并将数据存入字典,从而得到包含所有需要填入文档的数据的字典。最后使用DocxTemplate库将字典中的数据嵌入进文档中
1 | # 包含所有需要填入文档的数据的字典 |
DocxTemplate库中的render函数会识别Word文件中的占位符{{...}},并将字典中的数据一一对应进行填充
1 | 我叫{{name}},今年{{age}}岁------DocxTemplate.render(Tag)------>我叫张三,今年100岁 |
1、脚本
Windows电脑上有一类文件叫做批处理文件,后缀名是.bat。.bat文件是可执行文件(可直接双击运行),由一系列Dos命令构成,其中可以包含对其他程序的调用
对Python程序,若不使用Pycharm、Jupyter等编程软件,既想要实现双击直接运行的效果,又想要看到程序运行的过程,怎么做呢?

可以使用bat脚本实现。简单看个例子,编写个脚本:输出前20位斐波那契数列
(1)编写python程序,文件名为FBNQ_seq.py,输出前20位斐波那契数列
1 | # 初始数据 |
(2)在同一文件夹中创建bat文件,文件名为start.bat,写入以下指令
1 | @echo off |
(3)完成,双击start.bat即可运行
2、自动生成文档
在不了解自动生成文档的时候如果去猜其实现方法,通常会进入一个误区:“自动生成文档脚本”的难点在于生成文档,需要专注于去实现该功能(写者也曾进入此误区)
根据实操,并非如此,其难点是隐藏在这几个字背后的数据处理
DocxTemplate库,可以自动将数据填充进文档模板中,这个库实现的就是生成文档功能
但数据从哪来呢?需要我们自己处理;模板从哪来呢?需要我们自己处理
所以自动生成文档脚本的制作,难点其实在于数据处理这部分的代码编写以及模板的制作:
- 数据处理难点:一是要读取Excel的数据,二是要对每个占位符中的标识符进行赋值
- 模板制作难点:要对文档中需要修改的数据用占位符+标识符的形式进行命名,并且数据不一样或者数据含义不一样的地方需要使用不同的标识符,也就是每个数据的标识符都是唯一的
制作流程
(1)文档预览
以下是要自动生成的文档,标黄处是需要我们进行修改的地方

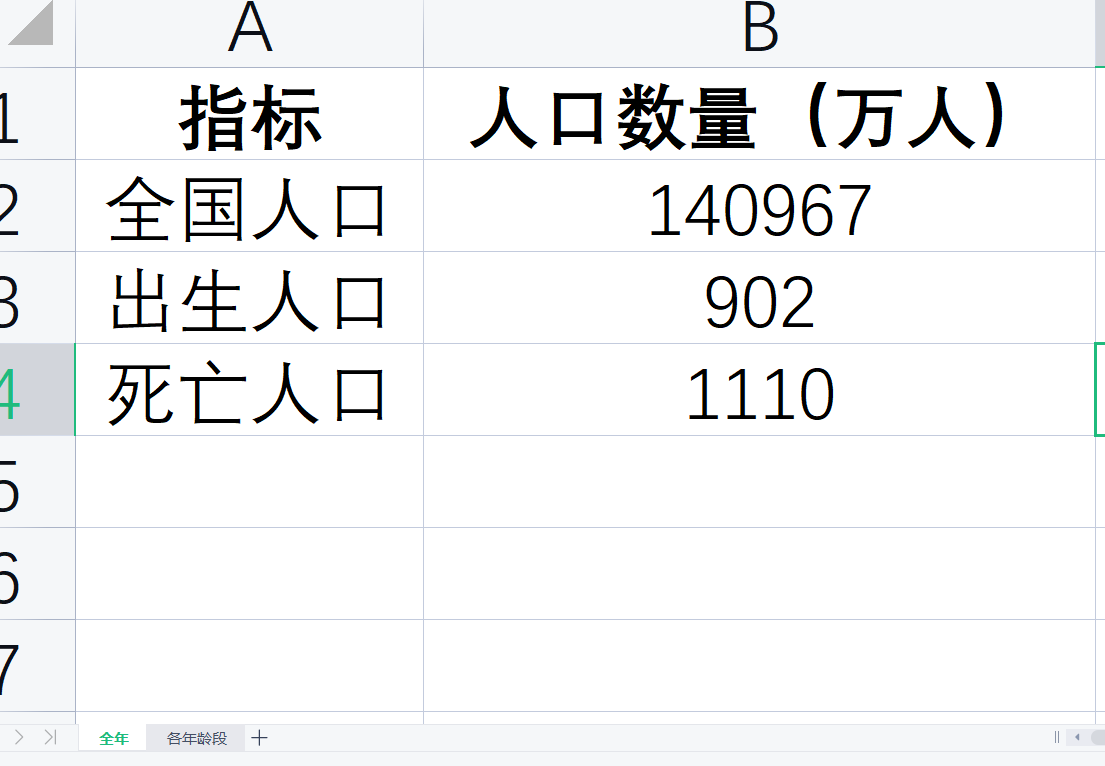
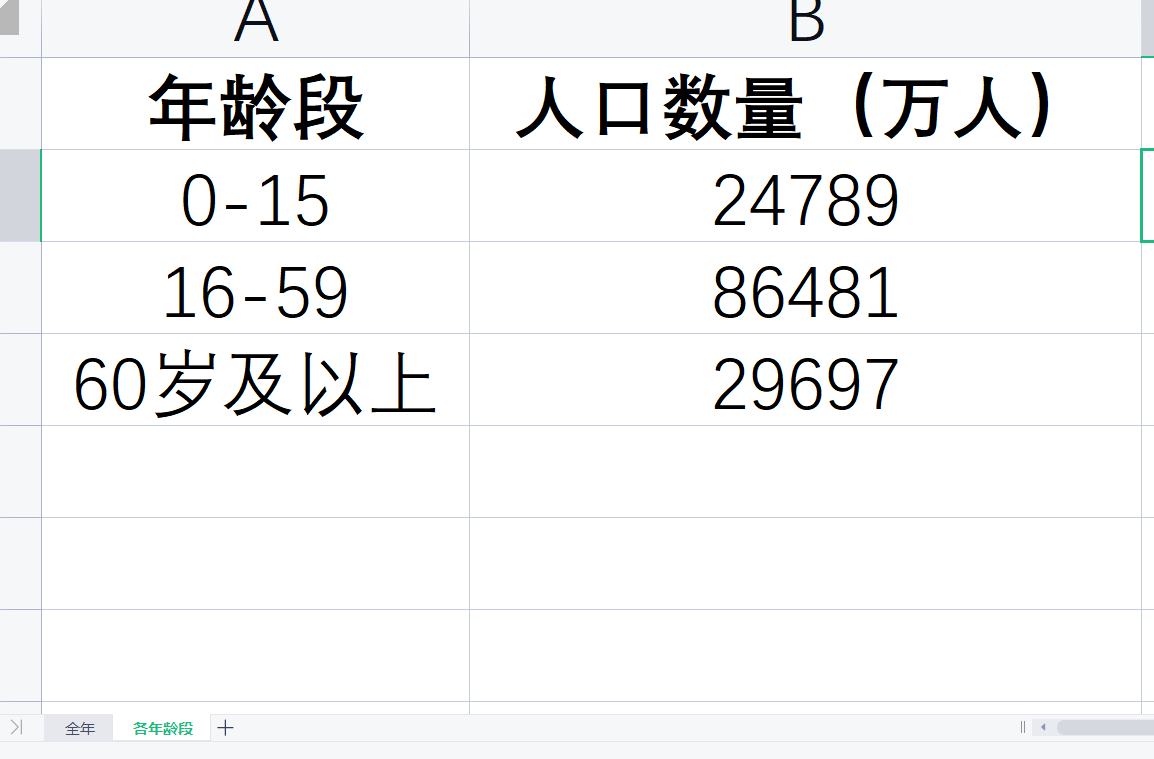
(2)数据预览
这是对应的数据表Excel,包含两个Sheet页
(3)创建模板
根据已有的文档,创建对应的文档模板。使用占位符来代替要修改的内容,然后占位符中需要使用唯一的字符串标识来映射这个数据

(4)处理数据
读取Excel,创建一个包含所有数据的字典,最终使用DocxTemplate将数据填充进模板中
①导库
1 | import datetime |
若没库,则需安装:
2
3
pip install docxtpl -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
②初步处理
针对文档模板中的所有标识符,使用字典的键值对来存储数据
1 | # 创建结果字典,用于存储所有键值对 |
③读取excel,处理数据
模板中存在两个段落,两个段落的数据刚好对应excel表中的两个sheet,可以分别进行处理然后把数据复制进res_dict中
第一段:
1 | first_par = {} |
第二段:
1 | sec_par = {} |
所有标识符处理完后,可以输出一下res_dict验证代码是否有误
1 | # 输出最终字典,看下存储结果 |

至此,数据处理的代码全部完成,可以编写生成文档的代码了(🤫🤫🤫悄咪咪的说,生成文档的代码仅用三句即可实现)。
(5)生成文档
1 | # 给模板填充数据 |
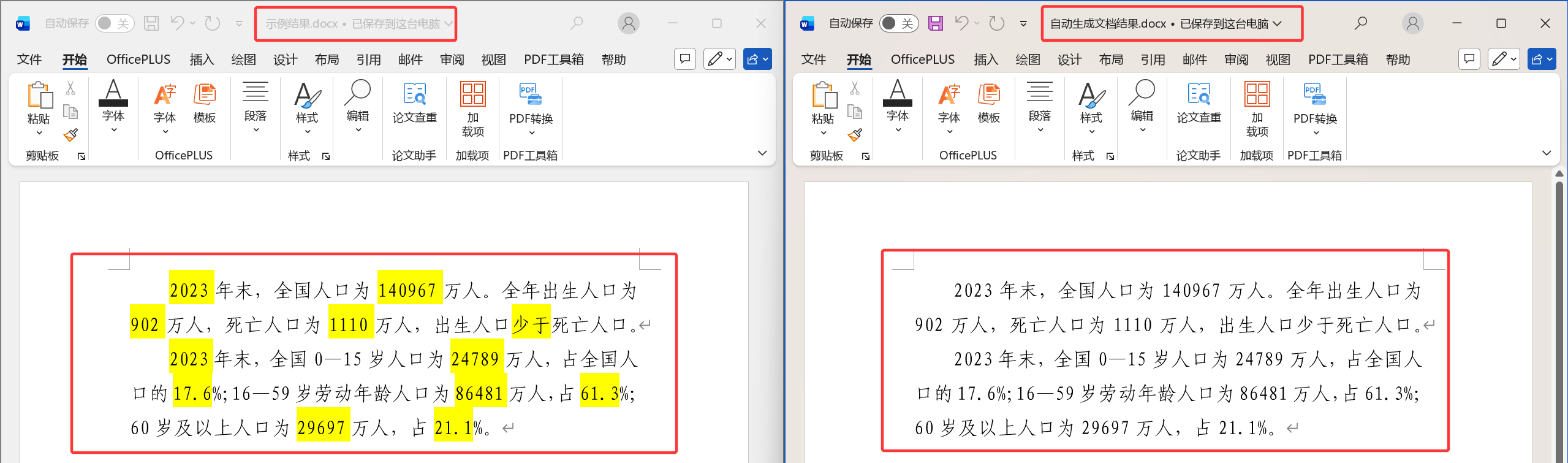
打开文件,进行对比,发现一模一样,成功!
(6)形成脚本
创建bat文件(方法:新建txt文本文件,后缀名改为bat),写入三行指令
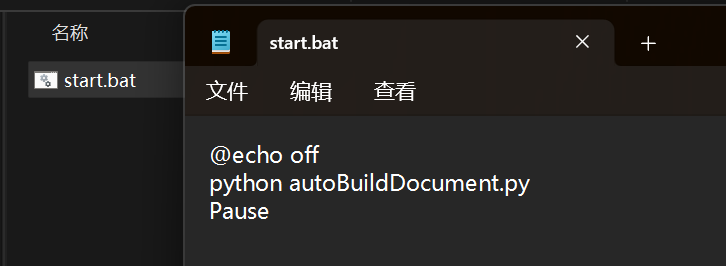
想要运行Python程序就可以直接双击这个bat文件
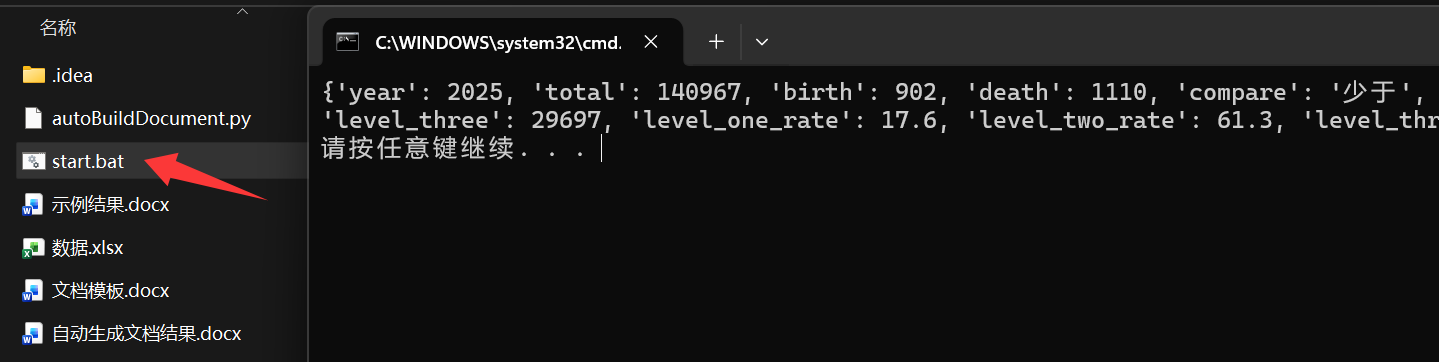
通览整个制作过程,会发现竟如此简单,且难点的确在于数据处理这部分的代码编写以及文档模板的制作,而生成文档的代码仅用三句即可实现
