机器学习笔记 - 决策树模型(一)CART决策树
决策树的基本原理非常简单,就是通过一系列类似于if/else…then…的逻辑推导判断,得到最后的结论
决策树按照算法划分有许多类型,包括ID3、C4.5、CART
CART决策树
CART决策树主要使用基尼指数进行运算,且CART树为二叉树,即只仅限于True&False的判断(左侧边默认是True,右侧边默认是False)
基尼指数gini(D): 用于计算一个系统中的失序现象,即系统的混乱程度(纯度)。基尼指数越高,系统的混乱程度就越高(不纯),建立决策树模型的目的就是降低数据集的混乱程度(提高纯度),从而得到合适的数据分类效果
数据集D的纯度可用基尼指数来度量,基尼指数越小,数据集D的纯度越高:
基尼系数的作用:
例如,现在有一份样本D,包含100名员工的离职情况数据(离职/未离职)
1、 假设这100名员工全是离职,那么离职的频率为100%,即P(离职)=1,那么该数据集的基尼值为,则表示该数据集没有混乱(或者说是纯度很高) ![meme-tuku]()
2、 假设样本数据中一半是离职员工,一半是未离职员工。那么员工被分为了两类,每类的频率都是50%,即P(离职)=P(未离职)=0.5,那么该数据集的基尼值为
,那么该数据集混乱程度相较于前一种情况就比较高了

当引入用于分类的特征后,如何选择哪个特征才是最优的分类变量呢?采取以下两步:
对于特征A条件下,样本集D的基尼指数为:
公式较为抽象,这里举例解释:
假设这些员工可以根据“满意度<5”这个特征进行划分,那么划分后的基尼指数为:公式可以简化为:
通过公式计算后,会选择划分后基尼指数最小的特征作为最优划分特征
1、初探
结合下述简易例子,可以更好的理解上述这两步所表达的意思:
现有一份100名员工离职情况的数据集,包含两个特征:满意度<5、收入<10000元,我们需要将这两个特征结合起来形成树状逻辑判断结构,也就是创建一个决策树,从而判断员工是否会离职
此处所谓的“创建一个决策树”,通俗的讲就是:是先判断满意度再判断收入 or 先判断收入再判断满意度呢?
以下是100名员工在这两个特征下的数据分类情况:
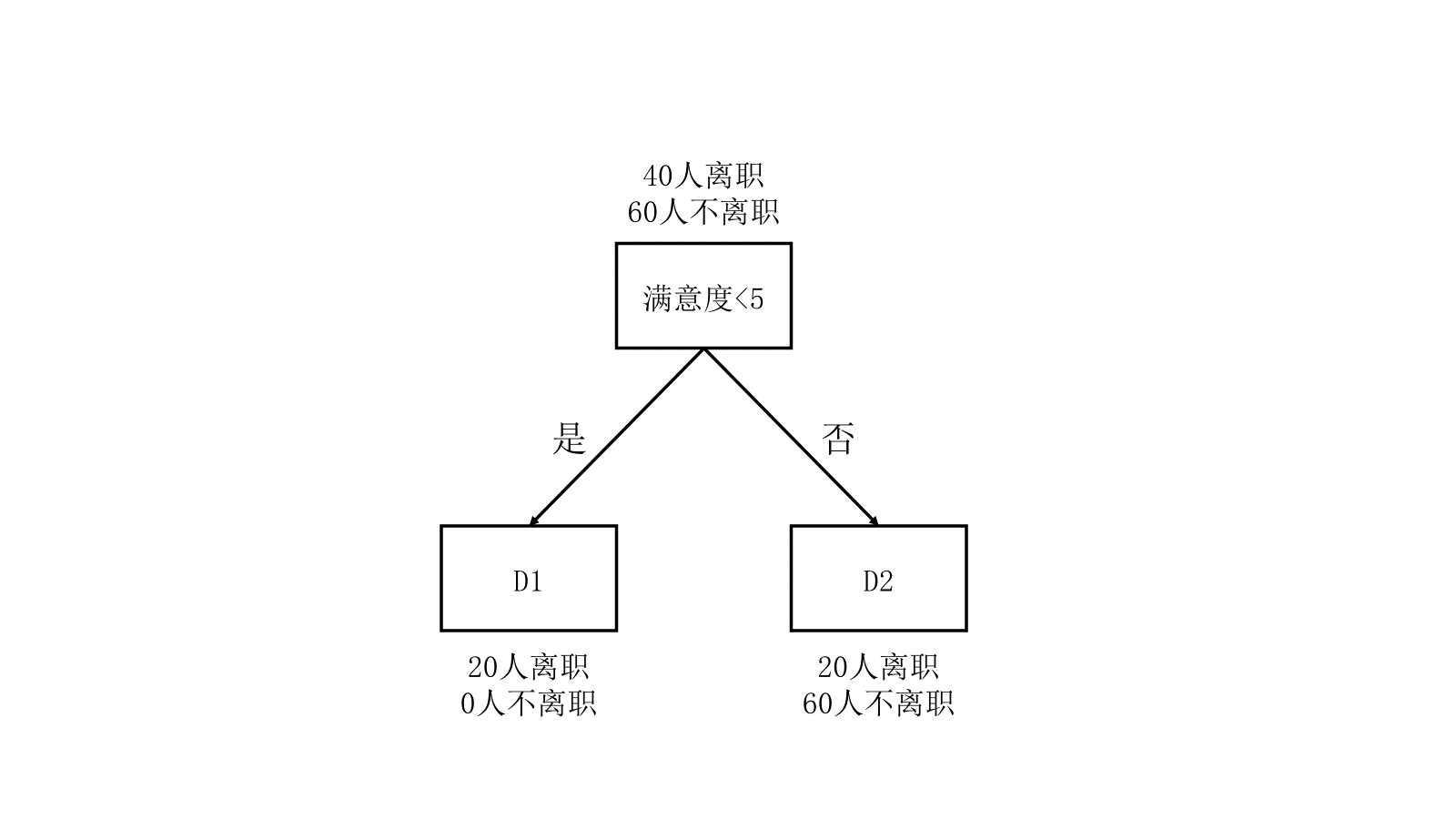
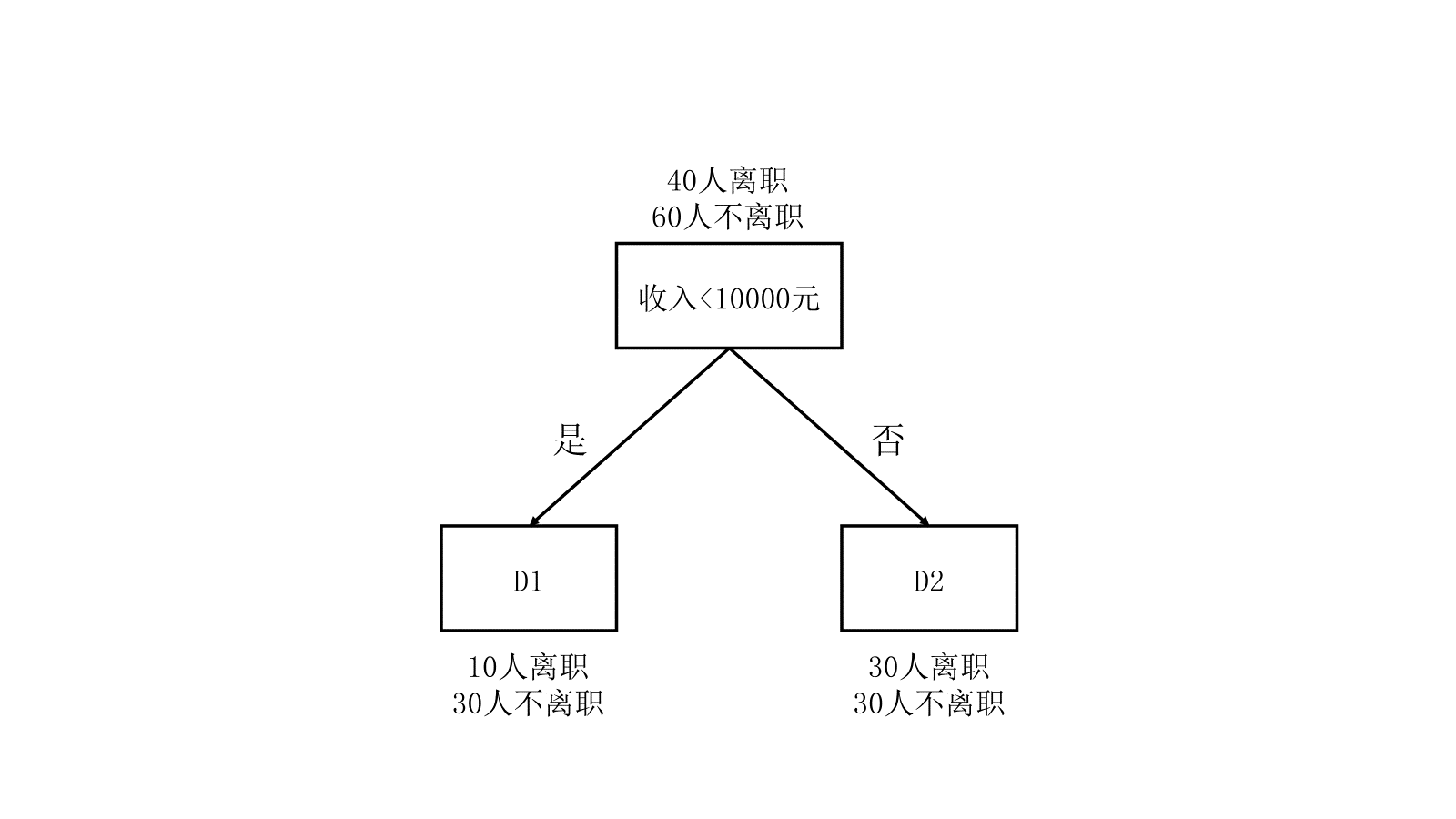
左图D1与右图D1无联系,左图D2与右图D2也无联系,仅为对样本群体的编号
我们分别对这两个特征分别计算基尼指数:
(1)计算以满意度进行划分后数据集的基尼指数(混乱程度)
以满意度<5作为根节点进行划分:
基于满意度<5特征划分后数据集D的基尼指数:
(2)计算以收入进行划分后数据集的基尼指数(混乱程度)
以收入<10000元作为根节点进行划分:
划分后数据集D的基尼指数:
(3)比较
基尼系数越低表示系统的混乱程度越低(纯度越高),区分度越高,表示越适合用于分类预测,因此选择“满意度<5”这个特征作为决策树的根节点
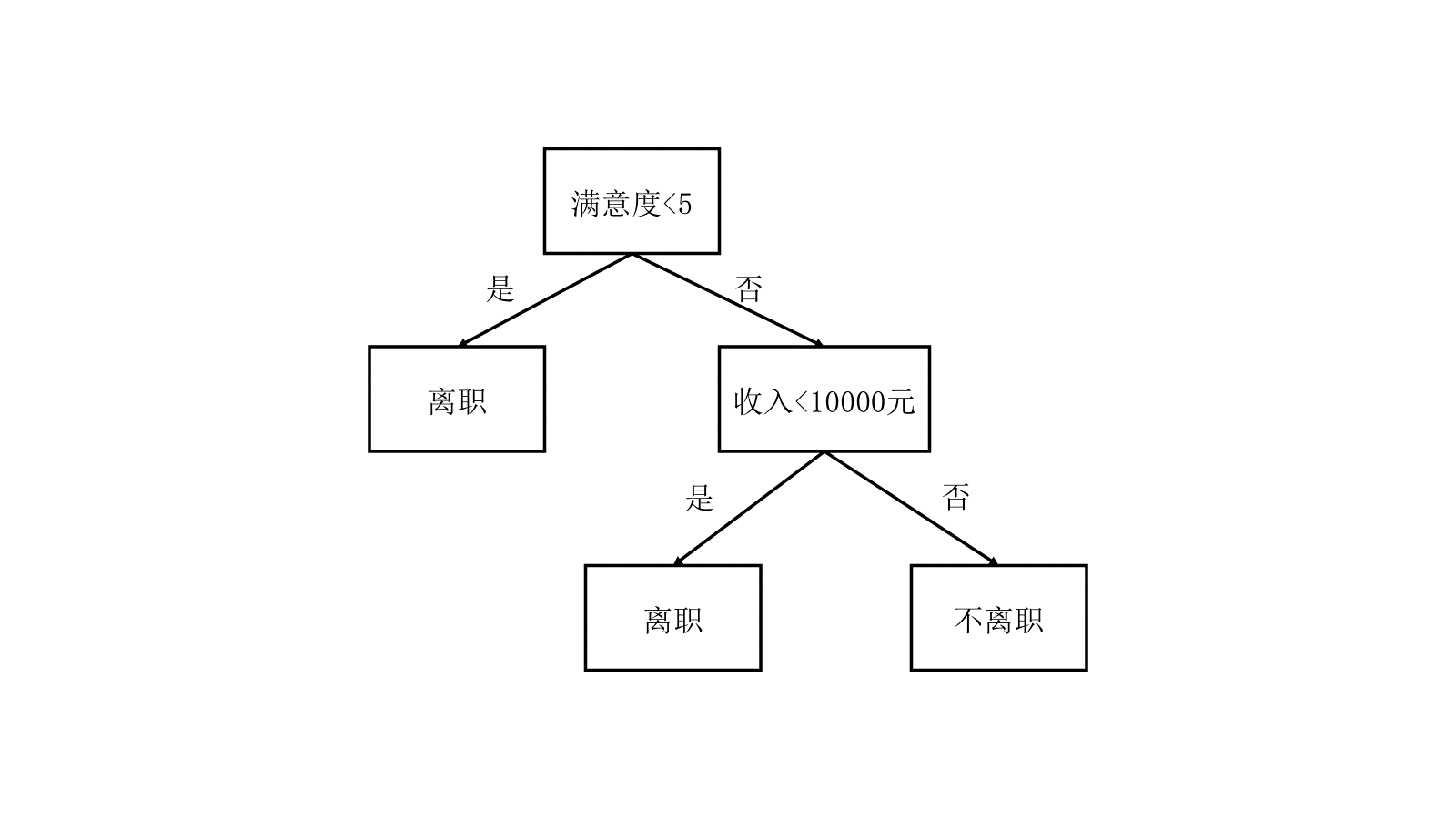
(4)最终结果
综上,我们的决策树将会是这个样子:
2、见路
以下是一份样表数据:
| 序号 | 是否有房 | 婚姻状况 | 年收入(k) | 是否拖欠贷款 |
|---|---|---|---|---|
| 1 | yes | single | 125 | no |
| 2 | no | married | 100 | no |
| 3 | no | single | 70 | no |
| 4 | yes | married | 120 | no |
| 5 | no | divorced | 95 | yes |
| 6 | no | married | 60 | no |
| 7 | yes | divorced | 220 | no |
| 8 | no | single | 85 | yes |
| 9 | no | married | 75 | no |
| 10 | no | single | 90 | yes |
这份样表数据包含1个结果变量(是否拖欠贷款)、3个分类变量(是否有房、婚姻状况、年收入)
(1)第一次特征选取
首先,我们先计算下这份数据的基尼指数了解这份数据的纯度(这步可省,写者看来除了能了解一下当前数据集混乱程度外对最后决策树的输出并无用途):
接下来我们需要分别计算这三个分类变量的基尼指数,从而选取第一个特征,即确定我们决策树的根节点
①以是否有房进行划分时:
| 是否有房/是否拖欠贷款 | 分类变量:是否有房 | ||
|---|---|---|---|
| Yes | No | ||
| 结果变量:是否拖欠贷款 | Yes | 0 | 3 |
| No | 3 | 4 | |
②以婚姻状况进行划分时:
| 婚姻状况/是否拖欠贷款 | 分类变量:婚姻状况 | |||
|---|---|---|---|---|
| single | married | divorced | ||
| 结果变量:是否拖欠贷款 | Yes | 2 | 0 | 1 |
| No | 2 | 4 | 1 | |
婚姻状况有3个值:single、married、divorced,考虑到CART决策树是二叉树,那么我们需要将这三个值进行二元划分:
{single} | {married、divorced}
{married} | {single、divorced}
{divorced} | {single、married}
上述三个公式计算过程看着似乎很繁琐,但熟悉前文内容后可按照第一个公式手动计算下,会发现计算过程并不难——对paper tiger必须重拳出击👊
对比计算结果,若使用婚姻状况特征作为根节点进行划分时要选取Gini指数最小的一个分组来划分结果,即:{married} | {single、divorced}
③以年收入进行划分时:
根据前面的内容可知,当属性是二分类(是否有房)时,可直接计算Gini指数;当属性是**(字符)多分类**(婚姻状况)时,需将属性进行二元划分(将n个元素分成两组,然后计算所有不同的二分类结果的Gini指数)选取Gini指数最小的一种划分方式,并取该划分方式的Gini指数作为该特征的Gini指数
那么当出现类似年收入这种数值型属性时,我们可以用两个数据的平均值来进行二元划分:首先需要对数据按升序排序,然后从小到大依次用相邻值的中间值作为分隔,将样本分为两组
例如当面对年收入60和70这两个值时,算得其中间值为65。那么就可以以中间值65作为分隔线将样本分为两组,继而求得Gini指数
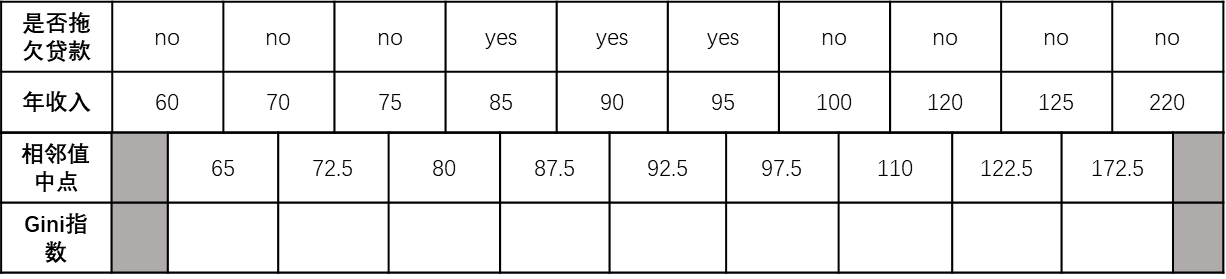
当划分点为中间值65时:
其余中间值依次计算……
拓展: 考虑到计算步骤较为复杂,此处通过编程来计算其余中间值的Gini指数(当作Coding练习):
1、 首先我们要确定一个合适的数据结构(结构体),用来存储数据,从而加以计算
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
# 中间值
'middle_value': int,
# 中间值左侧情况
'left_case': {
'length': int,
'True_count': int,
'False_count': int
},
# 中间值右侧情况
'right_case': {
'length': int,
'True_count': int,
'False_count': int
}
}以前文的中间值65为例,结构体将会是这个样子:
2
3
4
5
6
7
8
9
10
11
12
13
'middle_value': 65,
'left_case': {
'length': 1,
'True_count': 0,
'False_count': 1
},
'right_case': {
'length': 9,
'True_count': 3,
'False_count': 6
}
}结合前文的公式,我们就只需要将上述结构体代入公式即可计算出Gini指数
2、 定义一个函数giniCalculate(),将这个结构体作为参数传入进行计算,并返回Gini指数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
def giniCalculate(body):
# 设置常量10,即总样本数
total = 10
# 左侧分支Gini指数
left_gini = (1 -
Fraction(body['left_case']['True_count'], body['left_case']['length']) ** 2 -
Fraction(body['left_case']['False_count'], body['left_case']['length']) ** 2)
# 右侧分支Gini指数
right_gini = (1 -
Fraction(body['right_case']['True_count'], body['right_case']['length']) ** 2 -
Fraction(body['right_case']['False_count'], body['right_case']['length']) ** 2)
# 求Gini指数
Gini_index = (Fraction(body['left_case']['length'], total) * left_gini +
Fraction(body['right_case']['length'], total) * right_gini)
'''
此处的Fraction(A, B),指将A/B修改成分数的形式,而不是直接求得相除的结果,
比如Fraction(1, 2),就是将1/2表示成二分之一,而不是直接相除计算为0.5,
如果不表示成分数进行后续的计算,那会使得最后的计算结果存在误差
(通俗点来讲就是,把四舍五入后的数据进一步计算,那么得到的结果和正确的结果会有偏差)
'''
'''
float函数:将分数转为小数点表示形式
round函数:保留指定位数小数点,此处设置保留3位
'''
# 返回Gini指数
return round(float(Gini_index), 3)
'''----------测试代码----------'''
test = {
'middle_value': 65,
'left_case': {
'length': 1,
'True_count': 0,
'False_count': 1
},
'right_case': {
'length': 9,
'True_count': 3,
'False_count': 6
}
}
print(giniCalculate(test))
'''----------测试代码----------'''运行上述测试代码,输出0.4,成功!
3、 为了计算每个中间值的Gini指数,这里用两个列表存储原始数据(年收入、对应是否拖欠贷款),另外用两个空列表分别存放中间值和中间值对应的Gini指数
2
target_value = [False, False, False, True, True, True, False, False, False, False]
2
3
4
middle_value = []
# 每个中间值的Gini指数放在列表中
middle_gini = []
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
for i in range(len(value_nianshouru)-1):
# 临时变量
leftTemp_dict = {}
rightTemp_dict = {}
# 输出结构体
middle_res_dict = {}
left = i
right = i + 1
# 中间值
middle = (value_nianshouru[left]+value_nianshouru[right]) / 2
# 放入列表中
middle_value.append(middle)
# 将列表按中间值左右切分,分别计算左右两边True和False的数量
# 左边
left_lst = target_value[:i + 1]
leftTemp_dict['length'] = len(left_lst)
leftTemp_dict['True_count'] = left_lst.count(True)
leftTemp_dict['False_count'] = left_lst.count(False)
# 右边
right_lst = target_value[i + 1:]
rightTemp_dict['length'] = len(right_lst)
rightTemp_dict['True_count'] = right_lst.count(True)
rightTemp_dict['False_count'] = right_lst.count(False)
# 将所有数据按结构体形式存放到middle_res_dict中
middle_res_dict['middle_vlue'] = middle
middle_res_dict['left_case'] = leftTemp_dict
middle_res_dict['right_case'] = rightTemp_dict简单输出一下
print(middle_res_dict),看结构体是否按照需要进行输出:
完全正确!
最后在for循环内添加最后一句代码:
2
middle_gini.append(giniCalculate(middle_res_dict))4、 输出
2
print("Gini指数:"middle_gini)![firstselection-annual-income-gini-result]()
完整代码:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
def giniCalculate(body):
# 设置常量10,即总样本数
total = 10
# 左侧Gini指数
left_gini = (1 -
Fraction(body['left_case']['True_count'], body['left_case']['length']) ** 2 -
Fraction(body['left_case']['False_count'], body['left_case']['length']) ** 2)
# 右侧Gini指数
right_gini = (1 -
Fraction(body['right_case']['True_count'], body['right_case']['length']) ** 2 -
Fraction(body['right_case']['False_count'], body['right_case']['length']) ** 2)
# 求Gini指数
Gini_index = (Fraction(body['left_case']['length'], total) * left_gini +
Fraction(body['right_case']['length'], total) * right_gini)
'''
此处的Fraction(A, B),指将A/B修改成分数的形式,而不是直接相除,
比如Fraction(1, 2),就是将1/2表示成二分之一,而不是直接相除计算为0.5,
如果不表示成分数然后加以计算,会使得最后的计算结果存在误差
(通俗点来讲就是,把四舍五入后的数据进一步计算,那么得到的结果和正确的结果会存在一定误差)
'''
'''
float函数:将分数转为小数点表示形式
round函数:保留指定位数小数点,此处设置保留3位
'''
# 返回Gini指数
return round(float(Gini_index), 3)
value_nianshouru = [60, 70, 75, 85, 90, 95, 100, 120, 125, 220]
target_value = [False, False, False, True, True, True, False, False, False, False]
# 每个中间值放在列表中
middle_value = []
# 每个中间值的Gini指数放在列表中
middle_gini = []
# 从年收入的第一位开始遍历,直到倒数第二位
for i in range(len(value_nianshouru)-1):
# 临时变量
leftTemp_dict = {}
rightTemp_dict = {}
# 输出结构体
middle_res_dict = {}
left = i
right = i + 1
# 中间值
middle = (value_nianshouru[left]+value_nianshouru[right]) / 2
# 放入列表中
middle_value.append(middle)
# 将列表按中间值左右切分,分别计算左右两边True和False的数量
# 左边
left_lst = target_value[:i + 1]
leftTemp_dict['length'] = len(left_lst)
leftTemp_dict['True_count'] = left_lst.count(True)
leftTemp_dict['False_count'] = left_lst.count(False)
# 右边
right_lst = target_value[i + 1:]
rightTemp_dict['length'] = len(right_lst)
rightTemp_dict['True_count'] = right_lst.count(True)
rightTemp_dict['False_count'] = right_lst.count(False)
# 将所有数据按结构体形式存放到middle_res_dict中
middle_res_dict['middle_vlue'] = middle
middle_res_dict['left_case'] = leftTemp_dict
middle_res_dict['right_case'] = rightTemp_dict
# 调用giniCalculate,输入结构体,将return的结果存放到middle_gini中
middle_gini.append(giniCalculate(middle_res_dict))
print("中间值:", middle_value)
print("Gini指数:", middle_gini)

整理一下结果,如图:
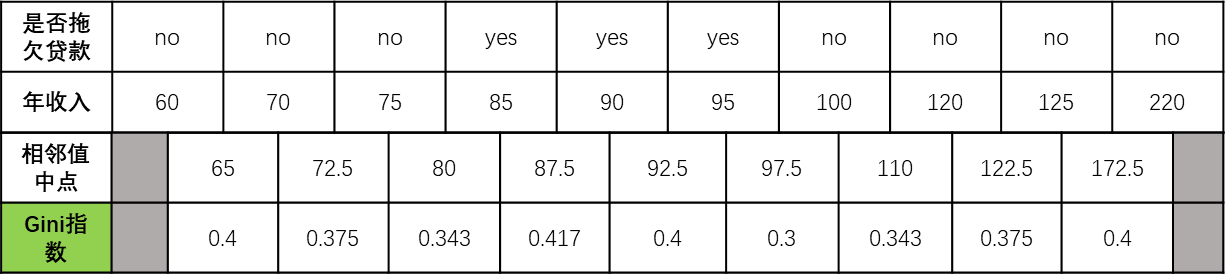
根据计算,发现当年收入取中间值97.5时,Gini指数为0.3,最小
④比较结果
当年收入取中间值97.5时,Gini指数为0.3,最小
同时根据前面计算,当婚姻状况按{married}|{single、divorced}划分时,Gini指数也为0.3,最小
即:划分根节点的三个属性(是否有房、婚姻状况、年收入)中,Gini指数最小的有两个:年收入(按97.5划分时)和婚姻状况(按{married}|{single、divorced}划分时),这里选取属性:婚姻状况,作为第一次划分(无所谓选谁,随意选),也就是根节点
(2)第二次特征选取
我们对前面的样表进行筛选,当婚姻状况为married时,“是否拖欠贷款”均为no;反选为single & divorced时,“是否拖欠贷款“有yes和no:
| 序号 | 是否有房 | 婚姻状况 | 年收入(k) | 是否拖欠贷款 |
|---|---|---|---|---|
| 1 | no | married | 60 | no |
| 3 | no | married | 75 | no |
| 7 | no | married | 100 | no |
| 8 | yes | married | 120 | no |
(需将以下样表继续划分)
| 序号 | 是否有房 | 婚姻状况 | 年收入(k) | 是否拖欠贷款 |
|---|---|---|---|---|
| 2 | no | single | 70 | no |
| 4 | no | single | 85 | yes |
| 5 | no | single | 90 | yes |
| 6 | no | divorced | 95 | yes |
| 9 | yes | single | 125 | no |
| 10 | yes | divorced | 220 | no |
首先,我们先计算下经过划分后这份数据的基尼指数,了解下这份数据的纯度:
接下来进一步选取属性进行划分
①以是否有房进行划分时:
②以婚姻状况进行划分时(没错,已经用作节点的属性还可继续使用):
③以年收入进行划分时:
这里借助前文的代码进行计算
1 | value_nianshouru = [70, 85, 90, 95, 125, 220] |
结果:
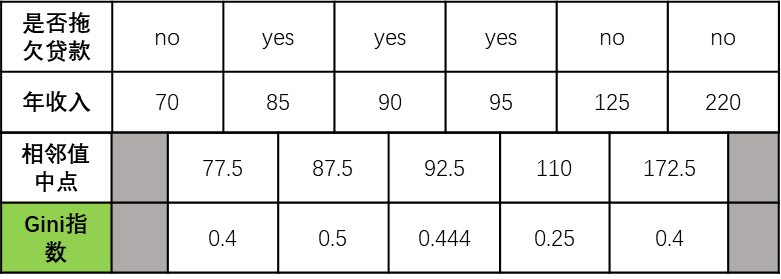
④比较结果
根据计算和对比,按是否有房来划分时,Gini指数为0.25,最小
同时,根据前面计算,按年收入中间值为110时,Gini指数也为0.25,也最小
这里选取属性:是否有房,作为第二次划分,也就是第二个节点
(3)第三次特征选取
我们对前面的样表进行筛选,当是否有房为yes时,“是否拖欠贷款”均为no;反选为no时,“是否拖欠贷款“有yes和no:
| 序号 | 是否有房 | 婚姻状况 | 年收入(k) | 是否拖欠贷款 |
|---|---|---|---|---|
| 9 | yes | single | 125 | no |
| 10 | yes | divorced | 220 | no |
(需将以下样表继续划分)
| 序号 | 是否有房 | 婚姻状况 | 年收入(k) | 是否拖欠贷款 |
|---|---|---|---|---|
| 2 | no | single | 70 | no |
| 4 | no | single | 85 | yes |
| 5 | no | single | 90 | yes |
| 6 | no | divorced | 95 | yes |
首先,我们先计算下经过划分后这份数据的基尼指数,了解下这份数据的纯度:
接下来我们进一步选取属性进行划分
①以是否有房进行划分时:
额外思考:当某个属性,并没有起到分类的作用时,那引入这个属性后的Gini指数将就是数据集的Gini指数。以这里的是否有房属性为例,这里全是no,这个属性并没有起到分类的作用,那最后我们求到的就是数据集的Gini指数,通过公式可以求证:
②以婚姻状况进行划分时:
③以年收入进行划分时:
这里借助前文的代码进行计算
1 | value_nianshouru = [70, 85, 90, 95] |
结果:
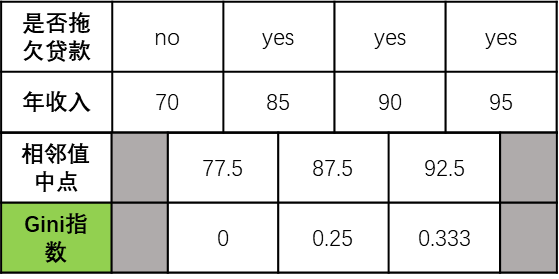
根据对比,当按年收入(中间值为77.5时) 来划分时,Gini指数为0,最小
因此第三个节点为 年收入
(4)特征选取结束,输出!
通过以上步骤,我们将得到这样一个决策树:
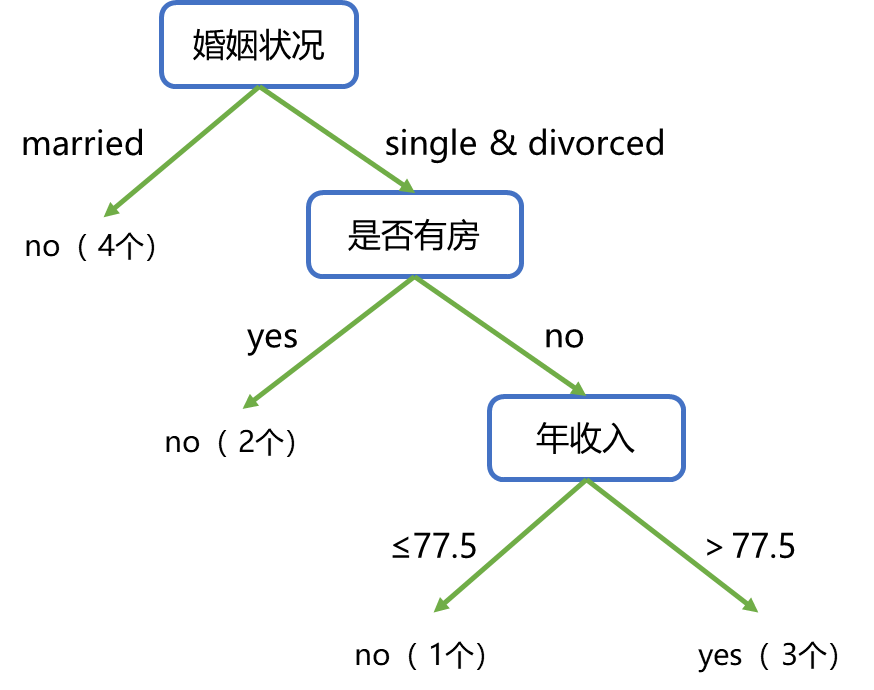
以上,便是使用CART决策树算法得到的一个决策树
上图中yes表示拖欠贷款,no表示未拖欠贷款,当有新的数据(包含婚姻状况、是否有房、年收入这三个分类变量)来临时,便可根据这个决策树来进行预测是否会拖欠贷款
在这次例子中,会发现有Gini指数相等的情况,那…是否意味着任何一份数据所生成的决策树并不一定时唯一的?事实的确如此!
3、践行
在前文两次例子中,我们都按照CART算法的逻辑,用手算加代码辅助计算的方式梳理了一遍,最终得到了一个CART决策树。但在现实实际应用场景下,终究是不能用一根笔杆子把涉及几百、几千甚至几万的数据集来进行计算。所以还是要用代码的方式处理上述数据集从而得到一个决策树
(1)数据集预处理
首先要处理下数据集,因为代码读取数据的时候没办法直接读取这些yes、no、single、married…..等等之类自定义的数据,我们用指定的数字来代替
比如是否有房,我们可以用0指代no,用1指代yes;
比如婚姻状况,我们用0指代married,用1指代single,用2指代divorced;
因为年收入本身是数字,所以我们不用设置
对于目标变量:是否拖欠贷款,我们同样用0指代no,用1指代yes
那么我们的数据集将会是这个样子:
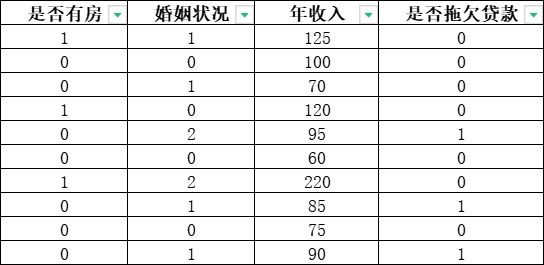
(2)决策树建模
①读取excel数据
1 | import pandas as pd |
数据集中,前3列是特征变量,最后1列是目标变量
我们需要切分下数据集df:
1 | # iloc函数会分别按行、列切分数据,逗号前指切分行,逗号后指切分列 |
可以
print(df)、print(x)、print(y)查看下处理后的数据是否符合要求
②调用sklearn库中的决策树算法
安装sklearn库:
1 | from sklearn.tree import DecisionTreeClassifier |
③调用graphviz,将生成的决策树导出为图片
Graphviz是一个开源的图可视化(graph visualization)软件,在这里可以借助这个工具画出决策树
以下是安装步骤(参照https://blog.csdn.net/2301_81199775/article/details/134761918),这个网页的安装步骤可能不太全,可参照写者的步骤:
0、(前置步骤)如果python已经安装了graphviz,可以先卸载
1、安装graphviz安装包(可自定义安装路径,需记住安装路径,后文需用到)
(windows64位)安装包文件名:windows_10_cmake_Release_graphviz-install-9.0.0-win64.exe
2、设置系统环境变量
打开系统环境,在Path中添加两个路径:
2
D:\Graphviz_DecisionTree\Graphviz\bin\dot.exe前面的
D:\Graphviz_DecisionTree\Graphviz\是graphviz安装位置(根据自己电脑安装位置为准,此处为写者电脑安装位置),重点在于后面的\bin和\bin\dot.exe,需要把这两个添加至系统环境变量中检验是否成功设置:打开cmd窗口,输入
dot -v,看是否会有如下结果:![graphviz-install-succeed]()
若有,则设置成功!
3、python安装graphviz
以下是相关代码:
1 | from sklearn.tree import export_graphviz |
输出:
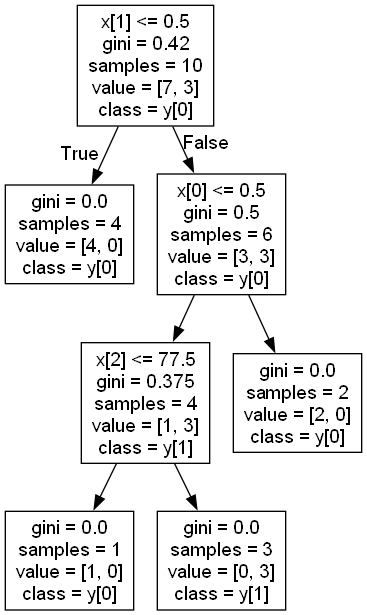
该决策树和前文手算得到的决策树一模一样!
Tips:但其实该决策树并不是数据集的唯一解,详见后文:random_state的作用
这里以第一个节点(根节点)为例,简述该如何理解图片中的这个决策树:
x[1]: 表示数据的第2个特征。这里重新翻看下前文经过数据预处理的数据集,数据集包含3个特征,从左往右依次是:是否有房、婚姻状况、年收入,代码排序是从0开始的,所以X[1]表示的是第2个:婚姻状况
gini: 表示当前数据集的gini指数。也就是前文提到的可以省略的那个步骤所求出来的数据,这里指的是Gini(D),不是Gini(D,A)
samples: 表示该节点的样本数。此处表示的就是初始数据集的样本数量,共10条数据
value: 表示该节点各个分类的样本数。此处的[7,3]表示的就是分类为0的有7个,分类为1的有3个,也就是前文设置的是否拖欠贷款中用0表示“否”,1表示“是”
class: 表示被划分为的类别,它是由value中样本数较多的类别来决定的。该节点中,分类为0(数组下标)的样本数为7,大于分类为1(数组下标)的样本数3,所以该节点的分类为0,也就是y[0],其他节点同理。(但可能有些节点不同分类的样本数相同,比如从上往下第二排、从左往右第二个的节点,不同分类的样本数均为3,然后该节点被划分的类别为0,这个并不影响,因为决策树是逻辑判断树状结构,我们需要关注的是经过一系列判断后的结果所被划分的类别,也就是叶子节点)
这里总共有4个叶子节点,那么有4条判断逻辑:
- 当婚姻状况≤0.5时,不会拖欠贷款;
- 当婚姻状况>0.5、是否有房≤0.5、年收入 ≤ 77.5时,不会拖欠贷款;
- 当婚姻状况>0.5、是否有房≤0.5、年收入>77.5时,会拖欠贷款;
- 当婚姻状况>0.5、是否有房>0.5时,不会拖欠贷款。
讲人话就是(在前文中,婚姻状况的3个状态分别是:0–结婚,1–单身,2–离婚):
- 当婚姻状况为 结婚 时,不会拖欠贷款;
- 当婚姻状况为 单身&离婚 、是否有房为 否 、年收入 ≤ 77.5时,不会拖欠贷款;
- 当婚姻状况为 单身&离婚 、是否有房为 否 、年收入>77.5时,会拖欠贷款;
- 当婚姻状况为 单身&离婚 、是否有房为 是 时, 不会拖欠贷款。
(3)决策树展示优化
上述代码输出的决策树,全是字符数字,观感较差。可以设置几个参数,简单优化下:
1 | from sklearn.tree import export_graphviz |
输出:
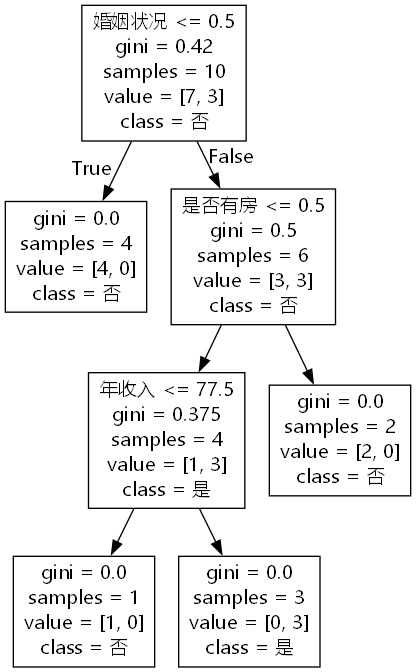
(4)特征重要性
我们可以输出一下各个特征的重要性,看看在这份数据集里面,哪个特征对结果的影响最大:
1 | clf_important = clf.feature_importances_ |
输出:
1 | 是否有房: 0.3571428571428571 |
根据数据,发现是否有房和年收入的重要性是一样的,然后婚姻状况相对来讲影响比较小
(5)须知:random_state的作用
决策树模型会优先选择使整个系统的基尼系数下降最大的划分方式来进行节点划分,但是可能不同的划分方式所获得下降程度是一样的,如果不对random_state参数进行设置,就有可能导致程序每次运行时会获得不同的决策树(这种现象在数据量较少时容易出现,当数据量较大时出现的概率则较小)
设置random_state主要是用于让结果可复现,实现可重复性的研究,不然可能会导致每次运行会出现不同的决策树,不利于后续的处理
回到前文中所提到的,代码运行得到的结果和手算的结果一模一样,其实是基于设置random_state=2得到的结果,如果不进行设置或设置为其他的数字,最终得到的结果大概会千奇百怪(至少对于这份数据集设置为None、0、1是这样的情况)
(6)须知:数字代替文本
在前文数据集预处理中有提到,对于涉及文本的多分类,例如性别分类:男、女或者婚姻状况:single、married、divorced……需要使用数字代替,才能使得代码能够识别;然后根据前面使用代码生成的决策树我们可以发现,决策树的分类方式是数字比大小,也就是<=。那么数字代替文本会导致一个什么情况呢?
先说写者的想法:不同的数字代替方式,最终生成的决策树大概率也会不同。在前面对于婚姻状况,我们的代替方式是:0指代married,1指代single,2指代divorced。在这里,之所以使用这个方式代替,并不是偶然,而是刻意,为了使代码生成的决策树与前面手算得到的决策树保持一致。以决策树的第一个分类为例,是判断是否结婚(married),手算的决策树只需要判断是不是married,而代码运算得到的则需要按数字比大小的方式,也就是<=0.5,按这种数字代替方式我们才能做到手算与代码保持一致。如果使用其他方式进行代替,例如0指代single、1指代married、2指代divorced,那生成的决策树也会不一样
深入思考一下:为什么会不一样?
对于多分类(除二分类以外的分类方式),如婚姻状况,分为married、single、divorced。我们人为分类可以直接进行分类,但是代码不行,必须使用数字代替后用数字比大小的方式进行分类。什么意思呢?即这种涉及文本的分类在代码层面本质上会变成前文所讲的年收入那种情况的数值型属性分类,也就是使用相邻两个数据的平均值来进行二元划分
很拗口,我们看下面这张图:
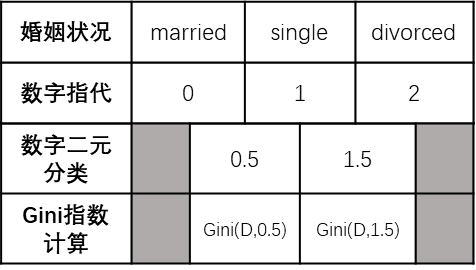
手算计算Gini指数计算最优分类是:
- Gini(D, married)
- Gini(D, single)
- Gini(D, divorced)
代码计算Gini指数计算最优分类是:
- Gini(D, 0.5)
- Gini(D, 1.5)
可以发现,代码计算多分类的Gini指数时,只会按二元划分的方式计算Gini指数从而判断最优分类,而不会按手算的方式针对某个单独的属性进行计算。在这种情况下,不同的数字代替方式可能会使得计算得到的最优分类不一样,导致最后生成的决策树也会不一样
Tips:因此,因为CART决策树在其底层逻辑算法的支撑下,生成的结果不具有唯一性(影响因素包括数据预处理时的人为设置与数据集本身),但其算法是唯一的。所以即使生成的结果与手算不一致,也不代表决策树就是错的